최대한 보고 들은 내용 그대로 정리하려고 노력했는데요.
뭔가 적다보니, 너무 불친절한가 싶기도 하네요. 😅
최근에 저도 회사에서 API 서버에 Kafka Producer가 여러개 붙으면서 서버가 갑자기 죽는 이슈가 발생했었는데요.
Grafana 모니터링하고 Visual VM을 이용해서 원인을 찾아서
JVM heapMemory를 튜닝해서 GC가 더 자주 돌게끔 바꿔 해결한 기억이 있어서,
재미있게 들었던 세션이었던것 같아요.
이 글에서는 메일이다 보니 수신거부를 해서 처리한게 인상깊었어요.
이 세션을 보기전에는 요청은 무조건 처리해야해.!! 라는 생각을 가지고 있었는데
상황에 따라 요청을 거부하는 방법도 취할 수 있겠구나 싶더라구요. ㅎㅎ
기회가 된다면 서버에 문제가 생기면 HTTP Cache를 활용하는 방법과,
자동화를 구현해보고 싶다는 생각이 드네요.
문제 상황이 발생하면 생각의 흐름을 어떻게 가져가야 할지도 배운 것 같아요.
듣고 정리한 내용이므로 잘못된 내용이 있을 수 있어요.
올바르게 지적해주시면 감사합니다. 🙂
11:00부터 진행한 TACK2의 첫번째 세션은 정지범 (NHN DOORAY)님께서 진행하신
"편안한 휴식 시간을 지켜줄 안정적인 백엔드 운영과 개발 기법" 입니다.
1. 자동재시작(self-healing)
- 서버의 재시작이 필요한 경우
- Garbage Collection Death Spiral (죽음의 소용돌이)
- 스레드 차단이 필요한 경우
- 서버에서 데드락이 발생한 경우
- Garbage Collection Death Spiral 원인
- 제한이 없는 요청 응답 레코드 수
- 해제되지 않는 객체 참조
- static class 변수 또는 싱글턴 패턴의 class 변수에 과도한 데이터 적재
장애 해결 작업의 무한 루프
-> 장애 발생
-> 장애 발생 전파
-> 관제시스템, 모니터링 툴 확인 (cpu, memory, disk 등 주로 리소스 확인)
-> Network 확인
-> 로그 확인
OutOfMemoryError 체크
주요 서비스 연동(httpClient, redis client, data source) 체크
-> 힙덤프, 스레드 덤프 남기기
-> 일단 서버 재시작
-> 장애 해소 전파
해결방법
1. JVM 실행옵션 이용
- - XX:+OnOutOfMemoryError = 'kill -9 %p' \
- - XX:+OnOutOfMemoryError = 'lb_out.sh; sleep 30; kill.sh %p' \
OutOfMemoryError가 났을때 해당 모듈을 정지, 그러나 OutOfMemoryError만 다루는것이 충분할까?
2. Spring-Boot Actuator HealthCheck Endpint 이용
- - K8S Liveness Probe, Rediness Probe로 잘 사용하는 Endpoint
- - 주요 기능 점검 기능
- DISK
- DataSource
- RabbitMQ
- Redis
# 예시
#!/usr/bin/env bash
function 건강한가요
{
health-$(curl -I http://localhost:9999/actuator/health 2>/dev/null | head -n 1 | cut -d$' '' -f2)
if [ $health -eq "200" ]
then
return 0
else
return 1
fi
}
위험관리
- 위험대응
- 정지 -> 생각 -> 호흡 -> 행동
- 성급한 대응은 상황을 악화시킴
- 자동화
- 반복된 패턴은 자동화 지향
2. 과부하를 처리하는 방법
- cascading failures
- cascading failures 시나리오

- 과부하로 인한 장애 사례 - 시스템 구성
- 발신 SMTP 서버에서 메일 발송
- 수신 SMTP는 Mail Box서버로 수신 처리 요청
- 초기운영중 시스템 장애
- 사용자가 겪는 장애내용
- 메일 수신 지연
- 메일 목록 조회 불가
- 메일 본문 조회 불가
- 사용자가 겪는 장애내용
- 지표의 측정(가시화)
- Spring Boot의 Actuator활용
- Metric과 Prometheus Endpoint 활성화
- Grafana 연동
- 측정 항목
- CPU사용률, Active Thread, 분당 Request수, 분당 메일 수신건수
- Active Thread 수
- 분당 메일 수신 건수
- Spring Boot의 Actuator활용
- 지표의 측정결과
- 장애시 Tomcat의 Thread pool을 모두 사용함
- 메일 수신량이 폭증함
- 메일 수신량이 많아도 메일크기가 크지 않으면 Thread Pool의 과도한 점유가 없음
- 메일의 크기가 큰 경우에 더 큰 부하가 발생 (메일 크기는 최대 40MB)
원인은 동시에 너무 많은 메일을 수신했기 때문 (Traffic Spike)
대응방안 확인
1. Scale Up/Out
- 리소스 사용량이 최번시에 급증, 최번시 사용을 위해 리소스를 늘리는 것은 비효율적인 비용이 발생
2. Message Broker로 지연처리
- 메일 수신의 보장 Role을 클라이언트가 담당하고 있는 구조 (클라이언트가 확인 할 수 없음)
- 처리가 완료될 때 까지 Retry
3. laaS, K8s의 Auto Scale 사용
- 단시간에 폭증하는 요청을 Auto Scale이 Cover할 수 없음
- managed K8s가 아닌 환경에서 HorizontalPodAutoscaler를 구성하는 것은 Scale Out과 다블 바 없는 비용 이슈
4. Circuit Breaker Pattern
- Cascading Failure의 대표적인 해결법
- 이미 서버에 부하가 발생한 후에 동작
- 장애가 일시적으로 사용자에게 노출
- 간헐적인 오류가 지속 노출
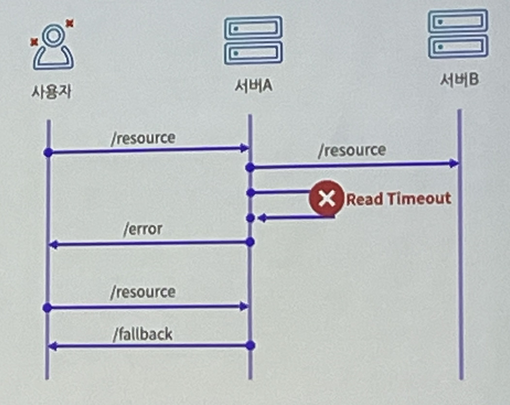
5. 수신거부 (Http Status Code: 429) 이방법을 채택
- Too Many Request(429)
- http status code
- 기준을 초과한 상황에서 응답거부
- 사용자에게 노출되지 않는 API에 적용

- 환경과 기준
- 적용 가능한 API선장
- Too Many Request를 처리할 기준을 찾아야함
- Too Many Requests (429) 처리가 가능한 API
- 사용자 인터렉션이 없는 API
- 비용이 높은 API
- 클라이언트의 Retry가 구현된 API
- Too Many Requests (429)로 응답하기 위한 Threshold(기준)
- 초당 요청량
- 장점 : 구현이 쉽다
- 단점 : 서버의 처리량(TPS)를 일정하게 제한한다.
- CPU 사용량
- 연계 서버의 응답지연으로 백엔드 시스템에서 병목이 발생하는 경우, Cascade Failure 유발
- Active Thread 수
- 연계 서버의 지연을 반영하는 지표로 사용가능
- 중요한 API 서비스를 제공하기 위한 Thread Pool의 여분을 안정적으로 확보하는데 유리
- 초당 요청량
- Active Thread 수 비율 사용
- Spring Boot Acutuator의 MetricsEndpint 활용
- 스레드풀 전체 수 대비 사용 중인 스레드 수가 85% 넘어가면 응답거부
- tomcat.threads.config.max
- tomcat.threds.busy

3. 백엔드에서 HTTP Cache 활용
브라우져의 HTTP Cache
- 네트워크 리소스를 줄여 빠르게 페이지를 로딩하는 효과적인 방법
- Cache-Control 헤더
- Cache-Control: must-revalidate
- 캐시는 사용하기 이전에 기존 리소스의 상태를 반드시 확인
- 만료된 리소스는 사용금지
- ETag 헤더
- 응답하는 리소스의 버전을 제공
- 문법
- ETag: "<etag_value>"
- If-None-Match 헤더
- HTTP 요청을 조건에 따라 응답가능
- 클라이언트가 ETag를 If-None-Match 헤더에 포함
- 서버는 ETag를 비교하여 다른 경우에만 응답을 제공
- 서버 간 HTTP Cache 시나리오

- [Server] ETag 생성구현
- Resources의 최종 변경시간을 관리
- 최종 변경시간으로 Week ETag 생성하여 응답
- If-None-Match 헤더가 들어오면 최종 변경시간으로 리소스 변경을 확인
- WebRequest.checkNotModified(String etag)
- HTTP Cache 클라이언트
- RFC2616(HTTP/1.1)의 cashe-control 스펙을 지원하는 클라이언트
- Apache HttpClient-Cache
- 캐시한 Response Body를 저장할 공간 필요
- 기본설정 in-memory
- EhCache
- memcached
- 캐시한 Response Body를 저장할 공간 필요
- OkHttp
- JDK8 HttpURLConnection
주의할점
- Shared Cache 주의
- 기본설정 : public인경우만 cache
- HttpClient-Cache로 구현한 서버는 그 자체로 Shared(public) Cache역할
- API의 URL 외 인증 등 기타 정보로 데이터가 변경될 경우 사용하면 문제됨
- Method
- HTTP Cache는 GET에서만 적용됨
- Storage Backend
- Shared Cache는 데이터를 많이 보유할수록 Hit할 확률이 높아짐
4. Netty의 Writing Back Pressure 구현
Netty로 구현한 소켓서버
- 기능
- 사용자 클라이언트용 소켓 서비스
- TCP 세션 기반으로 동작
- 특성
- 사용자의 요청 데이터에 비해 응답 데이터 크기가 매우큼
- 이슈
- 클라이언트의 성능이 느리거나 네트워크 성능이 느린경우
- 소켓 서버의 OutOfMemoryError가 발생
OutOfMemoryError
- 환경
- Xmx256m - Xms256m
- 증상
- 서버 접속 후 초기에 빠른 속도로 응답
- 속도 저하발생
- 응답없음
- 서버는 OutOfMemory 발생
Netty의 Writing Process
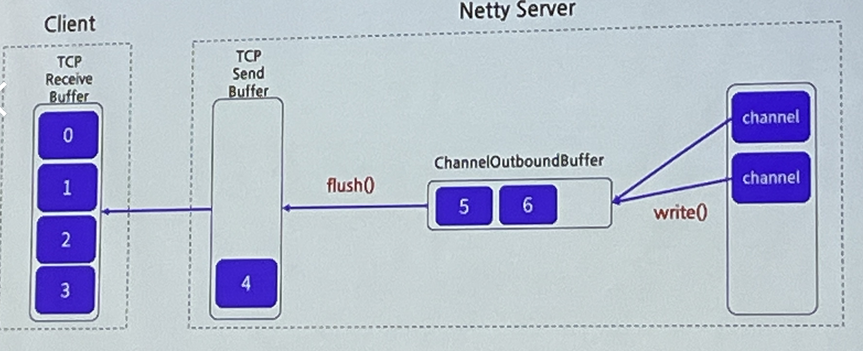
- Thread.sleep()
- 메모리는 안정적으로 유지
- 문제
- 응답데이터 100건/초 고정
- 클라이언트 상황에 맞는 Throttling이 필요
- Channel.isWritable() 사용
- 기능
- Write 가능 여부를 판단
- isWritable() 동작원리
- Write buffer에 데이터가 hige water mark를 초과하면 false
- Low water mark 아래로 떨어지면 true
- 기능
5. 마무리
편안한 휴식을 지키고 싶다면, 휴식시간에 ...
- 지속적인 작업
- 안정적 백엔드 운영은 한번으로 끝나지 않음
- 성능개선으로 기능 장애가 발생하지 않도록 테스트 코드 작성
- 가시화
- 개선에 대한 지표 확보
- 성과와 개선 방향을 얻을 수 있음
- 아이디어
- 반복작업 자동화
- RFC, W3C에 보석이 숨어 있음
다음 글은 분산 시스템에 관련한 주제의 세션 글을 올리려고 합니다.
정리하고 작성하다 보니 내용이 많아지네요. 그래도 끝까지 달려가겠습니다.
부족한 글 읽어 주셔서 감사합니다. 또한 잘못된 내용 있으면 지적해주시면 감사하겠습니다.
하얀종이개발자
'IT Conference' 카테고리의 다른 글
| 2023 카카오 제1회 tech meetup 참여 후기 (0) | 2023.05.23 |
|---|---|
| NHN FORWARD 22 컨퍼런스 정리 #1 (1) | 2022.12.17 |

