Java ORM 기술인 JPA를 사용하다보면 필수적으로 n+1문제를 맞닫뜨리게 됩니다.
내가 의도 하지않는 쿼리가 나가고 거기다 여러번 나간다면 정말 무섭겠죠.
왜 발생하고 어떻게 해결해 나가야 정리하면 좋을 것 같아 작성하려고 합니다.
해당 글은 JPA에 대한 기본적인 내용을 숙지하셔야 합니다.. 🙃
1. JPA n+1 문제가 무엇?
흔히 n+1문제라고 하는 것은 Lazy Loading을 사용하는 연관관계로 매핑된 엔티티를 조회할 때
의도치 않게 첫번째 쿼리로 날린 결과만큼 n번의 쿼리가 더 나가는 것을 말합니다.
간단히 코드를 짜보겠습니다.
여러명의 Member는 하나의 Team에 소속될 수 있는 엔티티 구조가 있다고 했을 때
Member 엔티티
@Entity
@Getter
@Setter
public class Member {
@Id @GeneratedValue
@Column(name = "MEMBER_ID")
private Long id;
private String username;
private int age;
@ManyToOne(fetch = FetchType.LAZY) // 지연로딩
@JoinColumn(name = "TEAM_ID")
private Team team;
@Override
public String toString() {
return ...;
}
}Team 엔티티
@Entity
@Getter
@Setter
public class Team {
@Id @GeneratedValue
@Column(name = "TEAM_ID")
private Long id;
private String name;
@OneToMany(mappedBy = "team") // 지연로딩
private List<Member> members = new ArrayList<>();
@Override
public String toString() {
return ...;
}
}
간단히 test code를 작성해서 team객체를 조회하고 team에 소속되어 있는 member객체를 호출 해보겠습니다.
// 더미 데이터 생성
@BeforeEach
void setup() {
for (int i = 0; i < 10; i++) {
Member member = Member.builder().username("member" + i).age(i).isDeleted(false).build();
memberRepository.save(member);
Team team = Team.builder().name("team" + i).build();
team.addMember(member);
teamRepository.save(team);
}
entityManager.flush();
entityManager.clear();
}
@Test
@Transactional
void findAll() {
List<Team> all = teamRepository.findAll();
for (Team team : all) {
System.out.println("team = " + team + ", " + "members = " + team.getMembers());
}
}
@Test
@Transactional
void findAllJoinFetch() {
List<Team> all = teamRepository.findAllJoinFetch();
for (Team team : all) {
System.out.println("team = " + team + ", " + "members = " + team.getMembers());
}
}
@Test
@Transactional
void findAllEntityGraph() {
List<Team> all = teamRepository.findAllEntityGraph();
for (Team team : all) {
System.out.println("team = " + team + ", " + "members = " + team.getMembers());
}
생성된 데이터와 쿼리가 어떻게 나가는지 보면?
- Team을 조회하는 쿼리 1개
- Team에 소속된 Members를 조회하는 쿼리가 N개
어라 분명 저는 Team을 모두 조회했고, Team과 Team에 소속된 member들을 호출했을 뿐인데
추가적으로 쿼리가 나가는 것을 알 수 있습니다.
위에서 말씀 드렸던 것 처럼
첫번째 쿼리(모든 Team을 조회)의 결과만큼 n번의 쿼리(Team과 연관된 Member)가 더 발생하는 문제
이것이 바로 JPA n + 1 문제 입니다.!!

2. 그러면 왜 문제가 생기는 건데?
Team이 엄청 많다면 Team 하나당 엄청많은 N번 만큼 조회하는게 문제가 되지 않을까요?
아니 한번 조회할 때 연관된 엔티티를 조인해서 가져오면 효율적인데 왜 이렇게 나갈까요?
문제는 TeamRepository 인터페이스에서 findAll() 메서드로 조회할 때 jpql이 동작하기 때문입니다.
jpql은 객체지향 쿼리로 엔티티의 객체와 필드이름을 가지고 쿼리를 만들게 되는데, findAll() 이 동작할때
"select t form Team t" 요렇게만 나가니깐 members를 호출할때 member는 지연로딩되어 객체 그래프에서 탐색하지 않고, member의 값을 사용할 때 연결된 객체를 찾기 위해서 다시 한번 쿼리가 나가게 되는거죠.
3. 어떻게 해결해야 하지?
우리가 원하는 것은 필요시에 연관된 엔티티까지 한번에 조회하는 join쿼리가 필요합니다.
이러한 쿼리를 말이죠.
SELECT * FROM team AS t JOIN member AS m ON t.team_id = m.team_id
- join fetch
그래서 JPQL에서 성능 최적화를 위해 기존 SQL의 조인 종류가 아닌 join fetch을 제공합니다.
연관된 엔티티나 컬렉션을 SQL 한 번에 함께 조회할 수 있죠.
@Query("select t from Team t join fetch t.members")
List<Team> findAllJoinFetch(); // Team 조회
List<Team> findTeams = TeamRepository.findAllJoinFetch();
for (Team team : findTeams) {
System.out.println("team = " + team + ", " + "members = " + team.getMembers());
}
이제 원하는 쿼리 한번만 나가네요. n + 1 만큼 쿼리가 나간 것에 비해 엄청 효율적으로 변했죠?
하나 주의해야 할 것은 join fetch는 지연로딩으로 설정해놓아도 우선순위를 가지기 때문에 즉시로딩으로 동작하게 됩니다. 뭐 당연한 이야기 같네요.
- @EntityGraph
JPA는 2.1 버전부터 엔티티의 연관관계과 있는 객체를 로드할 때 성능을 개선 하기 위해 @EntityGraph 기능을 제공하고 있습니다.
어노테이션으로 필드명을 지정하면 해당 필드가 지연 로딩이 아닌 즉시 로딩으로 조회 되는것 이라고 보시면 됩니다.
@Query("select t from Team t")
@EntityGraph(attributePaths = "members", type = EntityGraph.EntityGraphType.LOAD)
List<Team> findAllEntityGraph();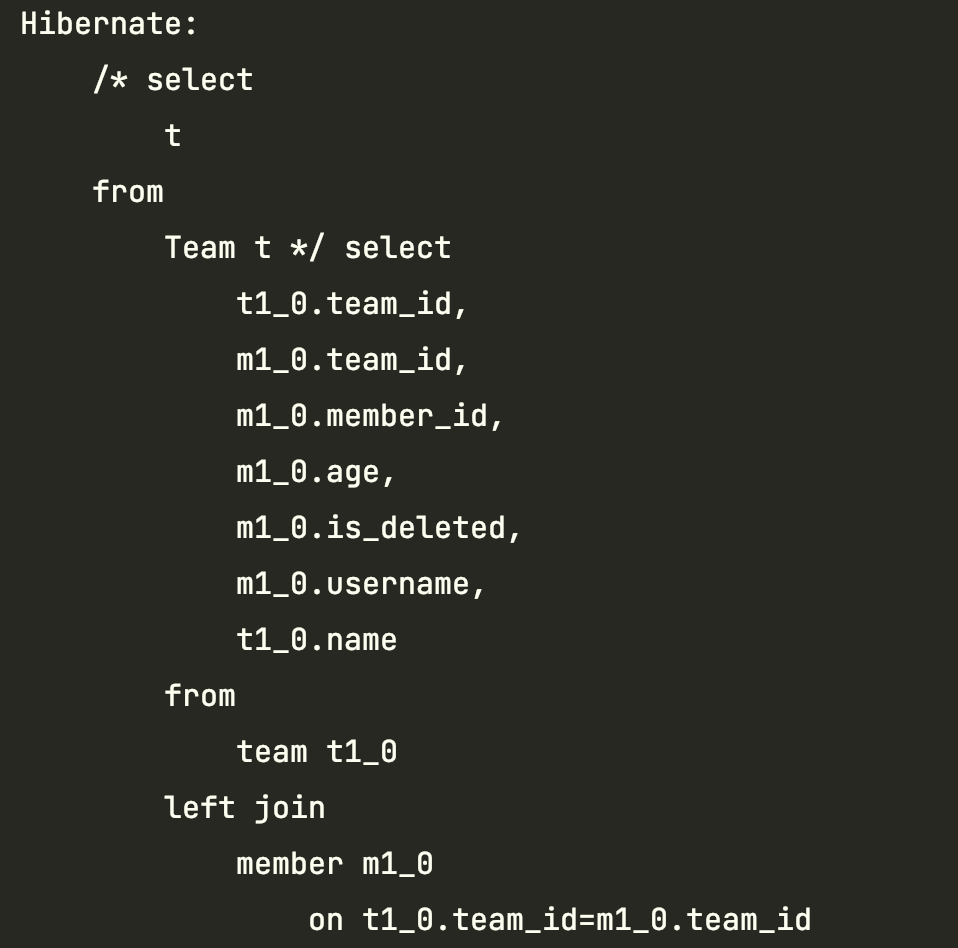
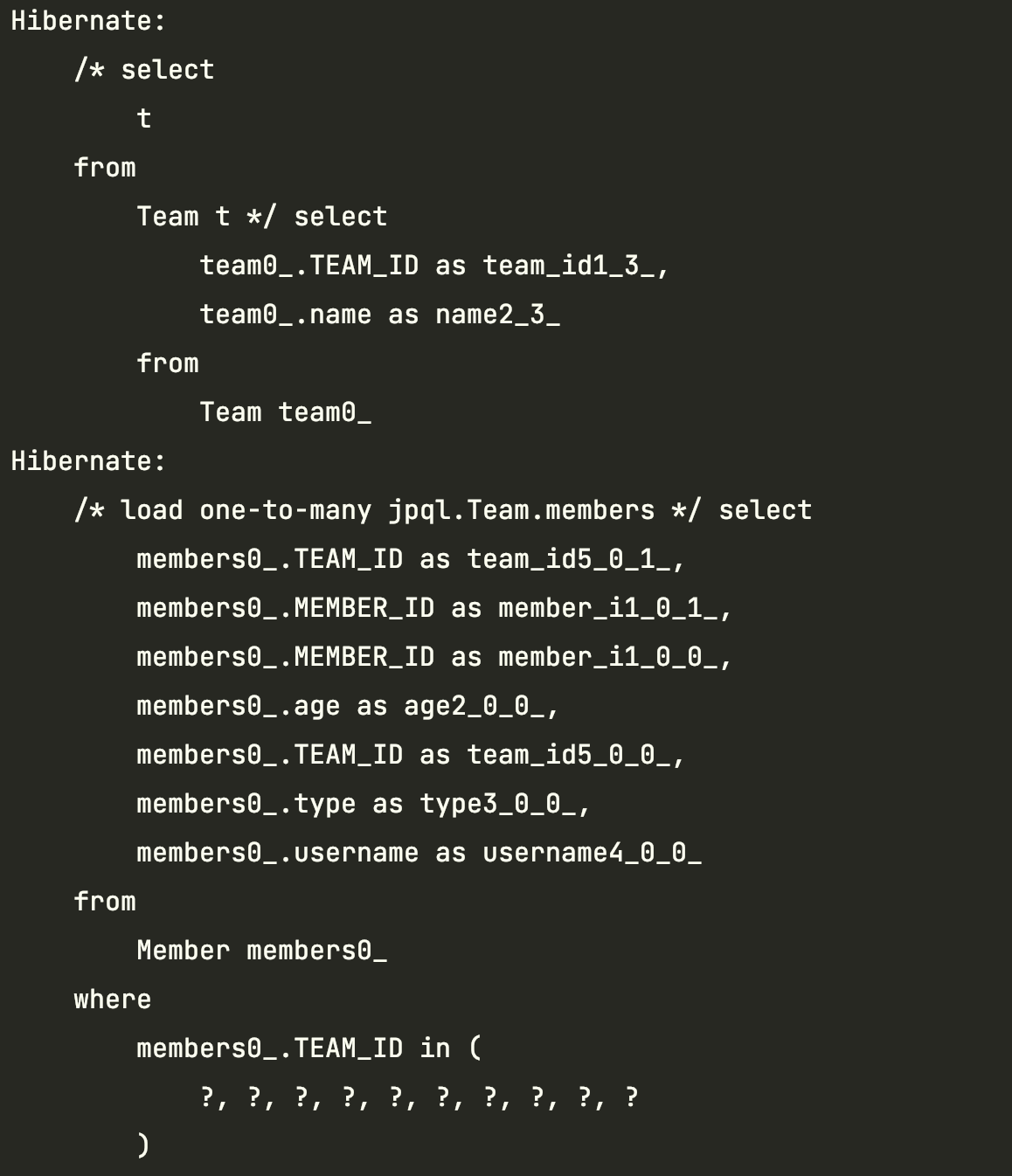
- @Batch-Size
JPA 의 성능 개선을 위해 하이버네이트의 옵션 중 하나로 연관된 엔티티를 조회할 때 지정된 size 만큼 SQL의 IN절을 사용해서 조회할 수 있게 합니다.
@Entity
@Getter
@Setter
public class Team {
...
@BatchSize(size = 100)
@OneToMany(mappedBy = "team")
private List<Member> members = new ArrayList<>();
...
}
4. 페치조인(join fetch)에 대해서 알아보자.
페치조인에 대해 좀 더 알아볼게요.
join fetch는 SQL의 일반적인 join의 종류는 아니고 JPQL에서 성능 최적화를 위해 제공하는 기능입니다.
핵심은 연관된 엔티티나 컬렉션을 SQL 한 번에 모두 조회하는 것 입니다.
페치조인과 일반조인의 차이
일반조인으로 나가면
// 일반조인으로 나가면
[JPQL]
select t from Team t join t.members m
[SQL]
SELECT T.* FROM TEAM T INNER JOIN MEMBER M ON T.ID=M.TEAM_ID
// 페치조인으로 나가면
[JPQL]
select t from Team t join fetch t.members
[SQL]
SELECT T.*, M.* FROM TEAM T INNER JOIN MEMBER M ON T.ID=M.TEAM_ID
일반 조인 실행시 연관된 엔티티를 함께 조회하지 않네요.
JPQL은 결과를 반환할 때 위에서도 말했듯이 객체와 필드를 가지고 생성하기 때문에 연관관계를 고려하지 않아요.
단지 SELECT 절에 지정한 엔티티만 조회할 뿐인거죠.
그러나 페치 조인은 객체 그래프의 개념이 추가되어 연관관계를 고려해서 모두 조회하게 됩니다.
페치 조인의 특징
- 연관된 엔티티들을 SQL 한 번으로 조회 - 성능 최적화
- 엔티티에 직접 적용하는 글로벌 로딩 전략보다 우선
- @OneToMany(fetch = FetchType.LAZY) //글로벌 로딩 전략
- 실무에서 글로벌 로딩 전략은 모두 지연 로딩
- 최적화가 필요한 곳은 페치 조인 적용
페치 조인의 한계
페치 조인의 대상에 별칭을 사용하는 것을 피해라
Hibernate는 지원하지만 객체그래프 설계 의도에 맞춰 페치조인의 대상이 바뀌면 안됩니다.
객체 그래프는 연관된 객체는 모두 조회하는 것이 설계 목적// fetch join에는 별칭을 주면 안된다
"select t From Team t join fetch t.members as m";
// fetch join된 members를 where절에서 사용 하면 안된다
"select t From Team t join fetch t.members as m where m.username = '회원1'";
"select t From Team t join fetch t.members as m where m.age > 10";
둘 이상의 컬렉션은 페치 조인 할 수 없다.
일 대 다의 연관 관계에서 join은 데이터가 뻥튀기 되는 문제가 있어요. 그런데 둘 이상의 컬렉션을 조회한다?
데이터가 마구 늘어나 데이터 정합성에 문제가 발생 할 수 있게 됩니다.
컬렉션을 페치 조인하면 페이징 API(setFirstResults, setMaxResults)를 사용할 수 없다.
일대일, 다대일 같은 단일 값 연관 필드들은 페치 조인해도 페이징 가능 (다대일 구조로 바꿔서 페이징 처리)
정리
페치 조인은 객체 그래프를 유지할 때 사용하면 효과적 입니다.
여러 테이블을 조인해서 엔티티가 가진 모양이 아닌 전혀 다른 결과를 내야 하면, 페치 조인 보다는
일반 조인을 사용하고 필요한 데이터들만 조회해서 DTO 로 반환하는 것이 효과적 이겠죠?
부족한 글 읽어 주셔서 감사합니다. 또한 잘못된 내용 있으면 지적해주시면 감사하겠습니다. 🙏
Reference
https://inf.run/Y8jp 김영한님의 자바 ORM 표준 JPA 프로그래밍 - 기본편
자바 ORM 표준 JPA 프로그래밍 - 기본편 - 인프런 | 강의
JPA를 처음 접하거나, 실무에서 JPA를 사용하지만 기본 이론이 부족하신 분들이 JPA의 기본 이론을 탄탄하게 학습해서 초보자도 실무에서 자신있게 JPA를 사용할 수 있습니다., - 강의 소개 | 인프런
www.inflearn.com
https://jojoldu.tistory.com/165 기억보단 기록을 N+1 문제 및 해결방안
JPA N+1 문제 및 해결방안
안녕하세요? 이번 시간엔 JPA의 N+1 문제에 대해 이야기 해보려고 합니다. 모든 코드는 Github에 있기 때문에 함께 보시면 더 이해하기 쉬우실 것 같습니다. (공부한 내용을 정리하는 Github와 세미나+
jojoldu.tistory.com
https://vladmihalcea.com/n-plus-1-query-problem/ vlad_mihalcea hibernate의 N+1 쿼리
N+1 query problem with JPA and Hibernate - Vlad Mihalcea
Learn what the N+1 query problem is and how you can avoid it when using SQL, JPA, or Hibernate for both EAGER and LAZY associations.
vladmihalcea.com
https://www.linkedin.com/pulse/hibernate-n-1-problem-testing-possible-solutions-oleg-galimov Oleg Galimov hibernate n+1 문제
Hibernate N + 1 problem: testing possible solutions
The most common framework for object-relational mapping along with MyBatis is Hibernate. Today it is actually the standard for JavaEE applications.
www.linkedin.com
https://www.baeldung.com/jpa-entity-graph entity-graph Baeldung
하얀종이개발자
'Spring' 카테고리의 다른 글
| 회사에서 Spring Boot + mongoDB 트랜잭션 도입하기 (4) | 2023.06.06 |
|---|---|
| SpringDataJPA(스프링데이터JPA)를 뜯어보자 (0) | 2023.06.05 |
| 서블릿(Servlet)이 뭔지 궁금해? (0) | 2023.03.09 |
| 의존관계주입 or 의존성주입 with spring #3 (0) | 2023.01.24 |
| SOLID에 대해서 쉽게 알려줄게 with spring #2 (0) | 2023.01.23 |



