Word Embedding이란?
- 워드 임베딩은 단어를 컴퓨터가 이해하고, 효율적으로 처리할 수 있도록 단어를 벡터화하는 기술
- 워드 임베딩은 단어의 의미를 잘 표현해야만 하며, 현재까지도 많은 표현 방법이 연구
- 워드 임베딩을 거쳐 잘 표현된 단어 벡터들은 계산이 가능하며, 모델 투입도 가능
워드임베딩은 Deep Learning 분야에서 자연어처리에서 필수적으로 알아야할 개념입니다.
머신러닝, 딥러닝으로 학습을 시킬 데이터는 숫자로 나타낼 필요가 있습니다.
영어나 한국어나 모든 언어(자연어)들은 abcd, ㄱㄴㄷㄹ 이런식으로 수치화되어있지 않기때문에 특징들을 뽑아내서
수치화하게 되는게 이 과정을 워드임베딩 이라고 합니다.
즉 단어를 밀집 벡터(dense vector)의 형태로 표현하는 방법을 워드 임베딩(word embedding)이라고 합니다.
그리고 이 밀집 벡터를 워드 임베딩 과정을 통해 나온 결과라고 하여 임베딩 벡터(embedding vector)라고도 합니다.
먼저 인코딩(Encoding)에 대해 알아보겠습니다.
인코딩(Encoding)
- 기계는 자연어(영어, 한국어 등)을 이해할 수 없음
- 데이터를 기계가 이해할 수 있도록 숫자 등으로 변환해주는 작업이 필요
- 이러한 작업을 인코딩이라고 함
- 텍스트 처리에서는 주로 정수 인코딩, 원 핫 인코딩을 사용
인코딩 방법에는 2가지가 있습니다.
정수 인코딩
- dictionary를 이용한 정수 인코딩
- 각 단어와 정수 인덱스를 연결하고, 토큰을 변환해주는 정수 인코딩
- {'you' : 0, 'say' : 1, 'goodbye' : 2, ....} 이런 예시로 정수값으로 라벨링
원 핫 인코딩(One-Hot Encoding)
- 원 핫 인코딩은 정수 인코딩한 결과를 벡터로 변환한 인코딩
- 원 핫 인코딩은 전체 단어 개수 만큼의 길이를 가진 배열에 해당 정수를 가진 위치는 1, 나머지는 0을 가진 벡터로 변환

Sparse Represention (희소 표현)
- 벡터 또는 행렬(matrix)의 값이 대부분이 0으로 표현되기에 희소 표현(sparse representation)이라고 합니다.
- 그러니까 0과1로 되어있는 원-핫 벡터는 희소 벡터(sparse vector)입니다.
- 희소 벡터의 문제점은 단어의 개수가 늘어나면 벡터의 차원이 한없이 커진다는 점
- 또한 원-핫 벡터는 단어의 의미 또는 단어 간 유사도를 담지 못한다는 단점
Dense Representation (밀집표현)
- 밀집 표현은 벡터의 차원을 단어 집합의 크기로 상정하지 않습니다.
- 사용자가 설정한 값으로 모든 단어의 벡터 표현의 차원을 맞춥니다.
- 또한, 이 과정에서 더 이상 0과 1만 가진 값이 아니라 실수값을 가지게 됩니다.
- 벡터의 차원이 조밀해졌다고 하여 밀집 벡터(dense vector)라고 합니다.
- 희소 표현 : 강아지 = [ 0 0 0 0 1 0 0 0 0 0 0 0 ... 중략 ... 0] # 이 벡터의 차원은 10,000
- 밀집표현 : 강아지 = [0.2 1.8 1.1 -2.1 1.1 2.8 ... 중략 ...] # 이 벡터의 차원은 128
- ``` Ex) 10,000개의 단어를 가정
Distributed Representation (분산표현)
- 원-핫 벡터는 단어의 의미 또는 단어 간 유사도를 담지 못한다는 단점을 개선하고자 고안된 방법
- 분산 표현 방법은 기본적으로 분포 가설(distributional hypothesis)이라는 가정 하에 만들어진 표현 방법
분포 가설 : '비슷한 위치에서 등장하는 단어들은 비슷한 의미를 가진다'강아지란 단어는 귀엽다, 예쁘다, 애교 등의 단어가 주로 함께 등장하는데 분포 가설에 따라서 저런 내용을 가진 텍스트를 벡터화한다면 저 단어들은 의미적으로 가까운 단어가 됩니다.
- 분산 표현은 분포 가설을 이용하여 단어들의 셋을 학습하고, 벡터에 단어의 의미를 여러 차원에 분산하여 표현
- 요약하면 희소 표현이 고차원에 각 차원이 분리된 표현 방법이었다면, 분산 표현은 저차원에 단어의 의미를 여러 차원에다가 분산하여 표현
- 이런 표현 방법을 사용하면 단어 간 유사도를 계산할 수 있습니다.
- 분산표현 방법의 대표적인 모형이 2013년 Google에서 발표한 Word2vec.
Word2Vec
Word2Vec에는 CBOW(Continuous Bag of Words)와 Skip-Gram 두 가지 방식이 있습니다.
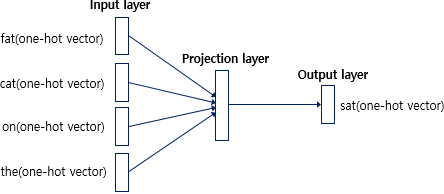
- CBOW는 주변에 있는 단어들을 가지고, 중간에 있는 단어들을 예측하는 방법입니다.
- Skip-Gram은 중간에 있는 단어로 주변 단어들을 예측하는 방법입니다.
CBOW
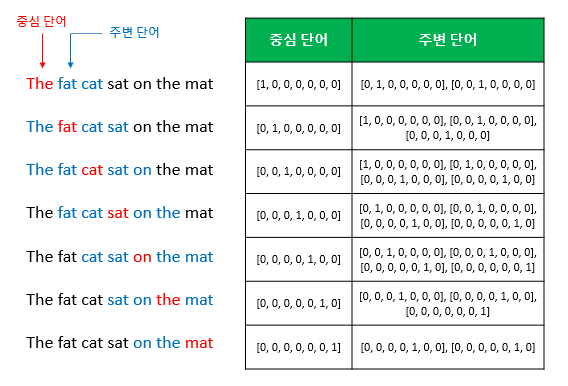
예를 들어, 갖고 있는 코퍼스에 아래와 같은 문장이 있다고 합시다. 예문 : "The fat cat sat on the mat"
- 가운데 단어를 예측하는 것이 CBOW라고 했습니다.
- {"The", "fat", "cat", "on", "the", "mat"}으로부터 sat을 예측하는 것은 CBOW가 하는 일입니다.
- 이 때 예측해야하는 단어 sat을 중심 단어(center word)라고 하고, 예측에 사용되는 단어들을 주변 단어(context word)라고 합니다.
- 중심 단어를 예측하기 위해서 앞, 뒤로 몇 개의 단어를 볼지를 결정했다면 이 범위를 윈도우(window)라고 합니다.
- 예를 들어서 윈도우 크기가 2이고, 예측하고자 하는 중심 단어가 sat이라고 한다면 앞의 두 단어인 fat와 cat, 그리고 뒤의 두 단어인 on, the를 참고합니다.
- 윈도우 크기가 n이라고 한다면, 실제 중심 단어를 예측하기 위해 참고하려고 하는 주변 단어의 개수는 2n이 될 것입니다.
- 윈도우 크기를 정했다면, 윈도우를 계속 움직여서 주변 단어와 중심 단어 선택을 바꿔가며 학습을 위한 데이터 셋을 만들 수 있는데, 이 방법을 슬라이딩 윈도우(sliding window)라고 합니다.
Skip-gram
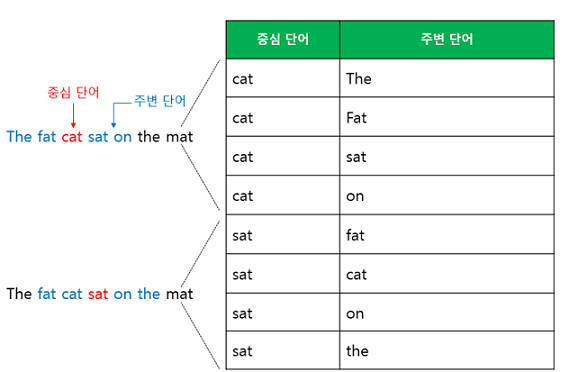
- CBOW에서는 주변 단어를 통해 중심 단어를 예측했다면, Skip-gram은 중심 단어에서 주변 단어를 예측합니다.
- 앞서 언급한 예문에 대해서 동일하게 윈도우 크기가 2일 때, 데이터셋은 다음과 같이 구성됩니다.
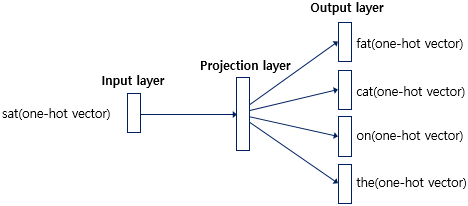
- 중심 단어에 대해서 주변 단어를 예측하므로 투사층에서 벡터들의 평균을 구하는 과정은 없습니다.
- 여러 논문에서 성능 비교를 진행했을 때, 전반적으로 Skip-gram이 CBOW보다 성능이 좋다고 알려져 있습니다.
글의 내용이 많아져서 2개로 나누어서 올리겠습니다. 긴 글 읽어주셔서 감사합니다.
'AI & Python' 카테고리의 다른 글
| 정규표현식(Regular Expression) with 파이썬 . ? + *기호 re.compile(), re.findall(), re.sub() (2) (0) | 2021.09.14 |
|---|---|
| 정규표현식(Regular Expression) with 파이썬 . ? + *기호 re.compile(), re.findall(), re.sub() (1) (0) | 2021.09.14 |
| 자연어처리, 워드임베딩 (Word2Vec, FastText , GloVe 예제)(2) (0) | 2021.09.09 |
| 딥러닝에서 가중치(W), 편향(Bias)의 역할 (3) | 2021.08.30 |
| 인공지능, 머신러닝, 딥러닝(AI, ML, DL)이 무슨 말? (0) | 2021.08.27 |



