
개념은 1부의 내용과 같습니다.
이제는 언어(자연어)를 수치화 해서 나열하는 방법은 여러가지인데요, 대표적인 3가지로 실습해보겠습니다.
Word2Vec, FastText , GloVe 순서입니다.
* Word2Vec (https://code.google.com/archive/p/word2vec/)
* FastText (https://github.com/facebookresearch/fastText)
- 빠르고 효율적입니다.
- 형태학적인 세부 사항도 끝납니다. FastText는 알 수 없는 단어에 대한 단어 벡터를 유도하거나 어휘에서 단어를 추출할 수 있기 때문에 고유합니다.
- Word2vec과 GloVe 둘 다 모델 사전에 없는 단어에 대한 벡터 표현을 제공하지 못합니다.
* GloVe (https://github.com/stanfordnlp/GloVe)
- GloVe는 말뭉치에서 집계된 전역 단어-단어 동시 발생 통계에 대한 훈련을 수행하는 단어 벡터 표현 방법입니다.
실습환경은 구글 Colab입니다.
Gensim Library
Gensim은 현대의 통계 기계 학습을 사용하여 감독되지 않은 주제 모델링과 자연어 처리를 위한 오픈 소스 라이브러리
!pip install gensim
!curl -c ./cookie -s -L "https://drive.google.com/uc?export=download&id=1V4rTx4yaAg0x1NY1MpNRY2Dp1nKeyOQ7" > /dev/null
!curl -Lb ./cookie "https://drive.google.com/uc?export=download&confirm=`awk '/download/ {print $NF}' ./cookie`&id=1V4rTx4yaAg0x1NY1MpNRY2Dp1nKeyOQ7" -o wiki_20190620_small.txt
Word2Vec 코드실습
import gensim
from gensim.models.word2vec import Word2Vec
path = '/content/wiki_20190620_small.txt'
sentences = gensim.models.word2vec.Text8Corpus(path)
model = Word2Vec(sentences, min_count = 10, size= 50, window = 5)
print(model)
vocabs = model.wv.vocab.keys()
print(vocabs)
print(len(vocabs))

model.save('w2v_model')
saved_model = Word2Vec.load('w2v_model')
# 이순신의 임베딩 벡터를 조회
print(model.wv['이순신'])
# 이순신과 유사성이 있는 데이터 10개 추출
print(model.most_similar(positive=["이순신"], topn=10))
# 이순신과 이명박의 유사성 수치 검색
print(saved_model.similarity('이순신', '이명박'))
# 이순신과 원균의 유사성 수치 검색
print(model.similarity('이순신', '원균'))
이순신을 검색했을때 가장 유사성이 있는 단어는 원균이라는 단어네요.
벡터화된 수치에 유사성과 관련된 수치가 담겨있기때문에
유사한 단어끼리 모여있어서 이걸 추출한다고 생각하시면 됩니다.
# 대한민국, 베이징과 유사성이 있는 단어 추출, 그러나 서울과는 관련이 없어야함
model.most_similar(positive=['대한민국', '베이징'], negative=['서울'])
대한민국은 나라, 베이징은 중국의 수도, 그러나 대한민국의 수도 서울과의 유사성을 제거하면?
중국과 관련된 단어들이 나옵니다. 모델안에 나라와 관련된 단어들이 모여있기 때문일꺼에요.
# 없는단어는 검색이 안됨
print(model.similar_by_word('카카오톡'))
모델안에는 카카오톡에 관련된 단어가 없기때문에 추출이 안됩니다.
FastText 코드실습
from gensim.models.fasttext import FastText
import gensim.models.word2vec
path = '/content/wiki_20190620_small.txt'
sentences = gensim.models.word2vec.Text8Corpus(path)
model = FastText(sentences, min_count=10, size=50, window=5)
print(model)
model.save('fasttext_model')
saved_model = FastText.load('fasttext_model')word_vector = saved_model['이순신']
print(word_vector)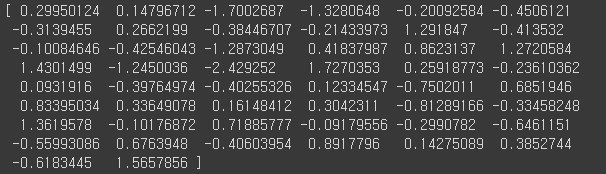
print(model.most_similar(positive=["이순신"], topn=10))
print(model.similarity('이순신', '이명박'))
print(model.similarity('이순신', '원균'))
이번에도 가장 유사성이 깊은 단어는 원균이네요. 연개소문이나 고려군은 왜 나왔는지 모르겠네요.
모델마다 값이 다 다르게 나옵니다.
model.most_similar(positive=['대한민국', '베이징'], negative=['서울'])
print(model.similar_by_word('카카오톡'))
FastText만의 특별한 장점은 단어의 유사성을 찾을때 형태가 비슷한것도 검색합니다.
Word2Vec 에서는 '카카오톡'이란 단어는 모델에 있는 데이터에 없어서 조회가 안되었는데
카카오, 사탕, 코코아등이 검색되는걸 보니 '카카오톡'의 카카오란 글자와 관련된 단어들이 조회되는것을 볼수있습니다.
GloVe 코드 실습
# glove는 word2vec과는 약간 다른 기술을 사용하는 다른 단어 임베딩이다.
# English만 가능
# 그러나 동일한 속성과 API를 가지고 있다.
import gensim.downloader as api
model = api.load("glove-wiki-gigaword-50")
model
model = gensim.models.KeyedVectors.load_word2vec_format('~/gensim-data/glove-wiki-gigaword-50/glove-wiki-gigaword-50.gz')
print(model)Glove는 2014년에 미국 스탠포드대학에서 개발한 단어 임베딩 방법론입니다. 기존의 카운트 기반의 LSA(Latent Semantic Analysis)와 예측 기반의 Word2Vec의 단점을 지적하며 이를 보완한다는 목적으로 나왔고, 실제로도 Word2Vec만큼 뛰어난 성능을 보여줍니다.
model.most_similar("queen")
model.similarity('husband', 'wife')
model.most_similar(positive=['korea', 'beijing'], negative=['seoul'])
# 한글 불가
model.similarity('한국')
# 모두 소문자로 이루어져있어서 대문자 불가
model.similarity('USA')저는 GloVe는 워드임베딩 모델이 유사도를 잘 잡는거 같아요.
그러나 모델에는 한글 데이터가없는게 아쉽네요.
이상으로 실습 예제를 마치도록하겠습니다.
긴 글 읽어주셔서 감사합니다. 예제코드도 한번 사용해보시면 좋겠습니다.
잘못된 내용 있으면 지적해주시면 감사하겠습니다.
하얀종이개발자
'AI & Python' 카테고리의 다른 글
| 정규표현식(Regular Expression) with 파이썬 . ? + *기호 re.compile(), re.findall(), re.sub() (2) (0) | 2021.09.14 |
|---|---|
| 정규표현식(Regular Expression) with 파이썬 . ? + *기호 re.compile(), re.findall(), re.sub() (1) (0) | 2021.09.14 |
| 자연어처리, 워드임베딩 (Word2Vec, FastText , GloVe 예제)(1) (0) | 2021.09.09 |
| 딥러닝에서 가중치(W), 편향(Bias)의 역할 (3) | 2021.08.30 |
| 인공지능, 머신러닝, 딥러닝(AI, ML, DL)이 무슨 말? (0) | 2021.08.27 |



